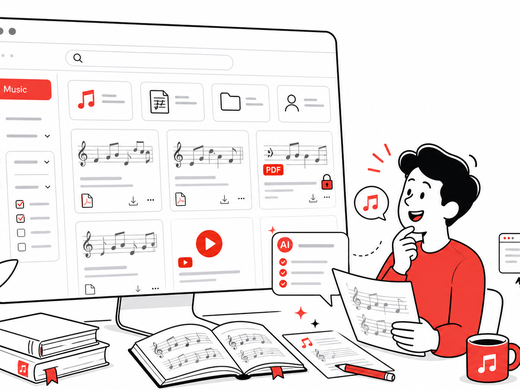
Wolfgang from Ondics built an open source sheet music catalog on CKAN — with AI metadata generation, YouTube playback, and cross-instance sharing. Here's how.
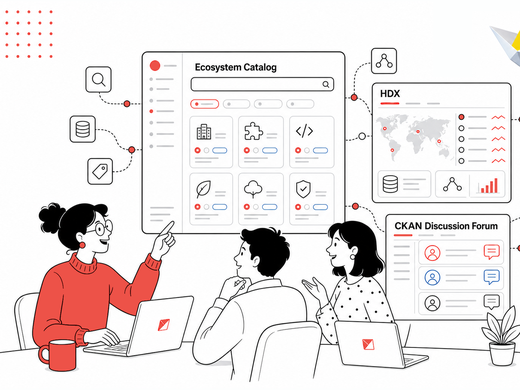
A recap of what the CKAN community covered on June 17, 2026: a live demo of the new CKAN Ecosystem Catalog, a deep-dive into HDX Tabular Data Endpoints, the launch of the new community discussion forum — and, surprise surprise, a very unexpected use of CKAN as a sheet music directory with AI-assisted metadata. Yes, really.