One of the biggest strengths of CKAN is the top-class support it offers for managing metadata. Data users and publishers know the importance of having robust and comprehensive metadata distributed in an interoperable way to really leverage the value of the published data.
From the flexibility that ckanext-scheming offers to define and manage custom metadata schemas to ongoing work to support standards like DCAT, metadata management is one of the core functionalities of CKAN. This functionality is now expanded with the release of support for the Croissant specification for describing Machine Learning (ML) datasets.
What is Croissant?
Croissant is a community standard championed by MLCommons that builds on top of general vocabularies like schema.org to address ML datasets specific needs. These include for instance, describing training and validation sets, including metadata to allow Responsible AI usage or the ability to combine structured and unstructured data sources.
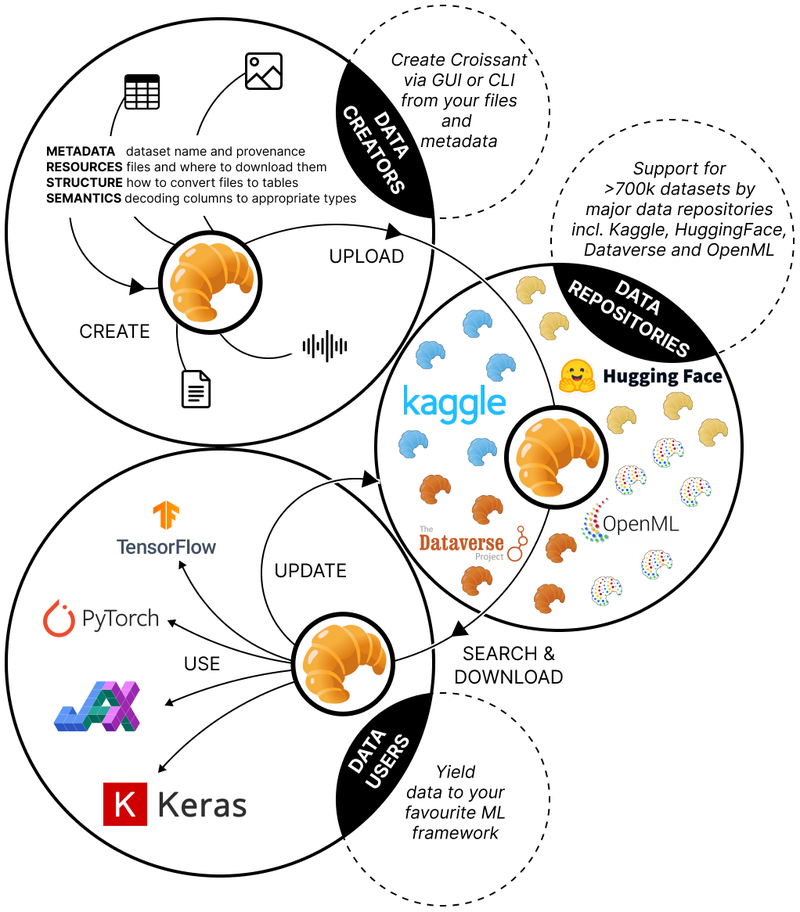
Although relatively recent, Croissant has gained major traction in the last year in the ML data ecosystem, with big AI platforms like HuggingFace and Kaggle already supporting it. CKAN sites can now join this emerging and vibrant space by using the croissant plugin.
The road to CKAN’s croissant support: a community-driven effort
The idea to integrate Croissant into CKAN was first proposed by CKAN co-steward Anuar Ustayev (Tech Lead at Datopian) in a GitHub discussion, where he suggested making ML datasets more discoverable and interoperable by adding Croissant support. The proposal sparked a debate on whether Croissant should be a standalone CKAN extension (ckanext-croissant) or integrated within the DCAT extension.
Following contributions from Omar Benjelloun (Croissant format author and Software Engineer at Google) and Darren Temple (a technologist at the The ODI - Open Data Institute) who demonstrated how a Croissant metadata profile could fit naturally within ckanext-dcat, aligning with how schema.org is already handled, CKAN core maintainers opted to include Croissant support directly in ckanext-dcat. This decision ensures easier adoption without requiring a separate extension.
Introducing the Croissant Plugin in CKAN
Now available as part of the just-released ckanext-dcat 2.3.0 version, the croissant plugin enables CKAN instances to expose ML dataset metadata in the Croissant format. Here’s what it brings:
It uses a custom profile to generate metadata for the site datasets following the Croissant format specification. This metadata is embedded in the dataset page source code and also accessible via a dedicated endpoint. CKAN's datasets are mapped to schema.org Datasets and resources to Croissant resources. Additionally, for resources that have been imported to the CKAN DataStore, the resource will also expose Croissant's RecordSet objects with information about the data fields (e.g. column names and types).
The croissant plugin can be used alongside other metadata plugins like dcat or structured_data to provide multiple representations of a dataset's metadata.
For those looking to fully leverage Croissant's capabilities, an example schema is available with all properties defined.
Get Involved and Provide Feedback
This is the first release of Croissant support in CKAN, and we encourage users to try it out and share their feedback. You can contribute by:
- Testing the Croissant plugin in CKAN
- Reporting issues or suggesting improvements in the GitHub repository
Special thanks to Darren Temple and the MLCommons Croissant working group for their support in getting this initial version over the line.