CKAN's new Datastore has been in development for a while. It's now finally been released with the latest version of CKAN, version 1.8. We're excited about the Datastore and we hope you will be, too. Let's have a look at what it offers to both data publishers and developers.
Overview
A CKAN instance can act as a registry for data, storing and serving metadata like title, URL, publisher, etc. It can also store the data, using the
Filestore and Datastore. While the Filestore stores entire files, the Datastore provides a database for structured storage of data together with a powerful API that allows easy create, read, update and delete operations.
A large data source is of limited use if not in structured form (such as a table); any application that uses the data needs it to have structure. The Datastore preserves the structure in your data and puts it behind a database, enabling queries and updates in situ. An application can query the data without needing to download the whole data file first - especially useful where the file is very large. One application that uses the Datastore is CKAN's built-in previewer using
Recline, which plots graphs and maps of tabular data.
For publishers
[caption id="attachment_2638" align="alignnone" width="500"]
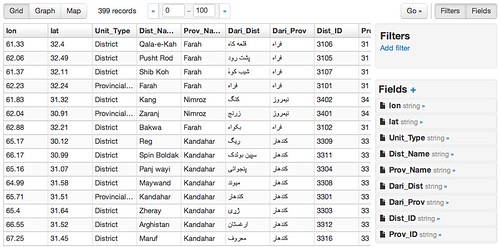
A preview of data from the DataStore in recline.[/caption]
The new version of the DataStore uses a full database for your data, unlike the old version which simply indexed it in a search engine. This means there is now a much more powerful machine interface (API) to the data (see below). For example, you can choose to update or add data points individually, rather than re-uploading an entire file.
An important improvement in searching is that queries can connect different resources together - greatly extending the possibilities for using your data, especially if you have used standard names (or Linked Data URIs) to identify the subjects of your data. For example, suppose you have some data indexed by country, using standard ISO country codes(
GB for Great Britain,
DE for Germany and so on). If there is another dataset also broken down by country code, we can easily combine the two and create a dataset that shows country-level patterns across the two data sources. The result will update itself automatically when one of the source resources changes.
In summary, the new DataStore helps ensure your data can be used easily in as many ways and by as many people as possible - including you.
For developers / data hackers
[caption id="attachment_2639" align="alignright" width="320"]
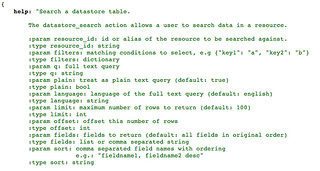
The datastore API returns JSON[/caption]
Let's have a quick look at how you might use the Datastore. The API is described fully in
the docs. While its create and update options are good news for publishers, developers will be most interested in the search and query capabilities. The new version of the Datastore uses an underlying PostgreSQL database, which enabled us to build a very powerful API. As described in
the documentation, there are three different API endpoints for searching. We'll look at each in turn.
SQL endpoint
The most powerful API endpoint is the
datastore_search_sql endpoint. This allows arbitrary SQL queries on the Datastore. Results are still returned as JSON, which you can easily use in your application. We tried to make the wrapper around the database as thin as possible; as a result, the SQL endpoint gives you full control over your query. You can filter and aggregate data from a resource, or combine it with other resources using joins, as in the example above. Joining and SQL search are the most powerful features of the Datastore for developers who want to work with the data, and we hope people will come up with many uses for them.
HTSQL endpoint
As an alternative to using pure SQL, there is an endpoint for
HTSQL. HTSQL is an easy to use, SQL-like language which you can use directly in a browser's location bar. At present the HTSQL endpoint does not allow joining resources, but we are working on a way to do that as well.
Search endpoint
If you don't need the full power of the SQL (or HTSQL) endpoint, you can use the
datastore_search endpoint. It allows exact matching of certain fields via
filters, or searching via the
query parameter. The
query parameter allows you to use PostgreSQL's full text search, which lets you search across all fields of a resource and returns a ranking of the results. To use full PostgreSQL text search, set the
plain parameter to
False. This enables queries as described in the
PostgreSQL docs. Again, we tried to make the wrapper as thin as we could to give you as much control as possible.
Interested? Check out the
documentation on how to get started. And why not use the DataStore API and data from
the DataHub at your next hack day? The DataHub is a public CKAN instance - create a group there for your event and upload data in advance.
As usual, please write to the
dev list with any questions, and we'll be happy to help.