Search
CKAN provides a rich search experience which allows for quick ‘Google-style’ keyword search as well as faceting by tags and browsing between related datasets. Users can quickly see what datasets are available, in which formats and with which licence, straight from the search results. All dataset fields are searchable (see below for the metadata we bring out into the interface).
Search on all dataset attributes – users can search on all dataset metadata, everything from title to tags to publisher name.
Full-text search – search full-text fields.
Fuzzy-matching – option to search for closely matching terms instead of exact matches.
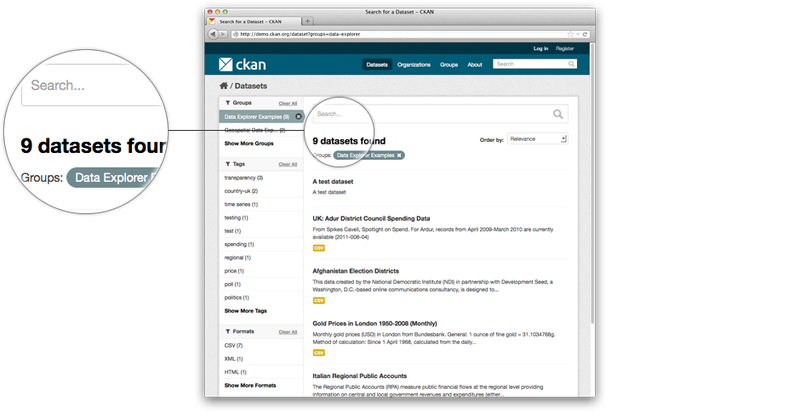
Faceted search – drill-down via facets – for example tags, format, licence, publisher. Ability to consecutively narrow the search by further facets allowing users to limit their search to datasets with specific formats or tags after they see the search results.
Search via API – All search facilities can also be made available over an API.
Metadata
A CKAN portal provides a rich set of metadata for each dateset.
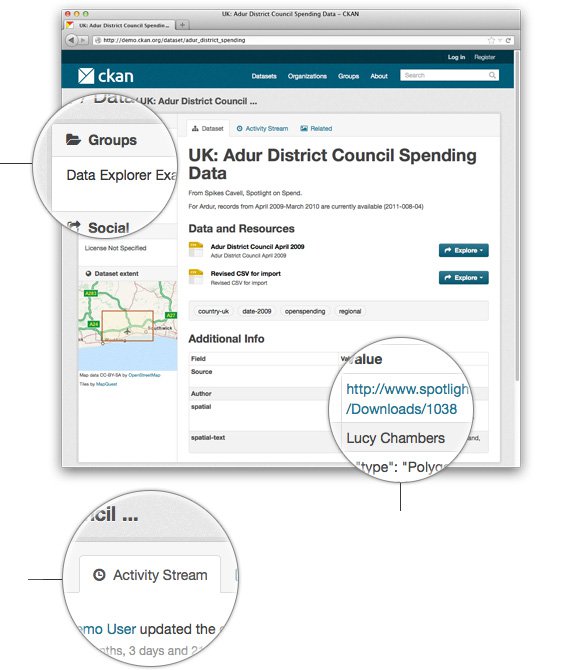
Title – allows intuitive labelling of the dataset for search, sharing and linking.
Unique identifier – dataset has a unique URL which is customizable by the publisher.
Groups – display of which groups the dataset belongs to if applicable. Groups (such as science data) allow easier data linking, finding and sharing amongst interested publishers and users.
Description – additional information describing or analysing the data. This can either be static or an editable wiki which anyone can contribute to instantly or via admin moderation.
Data preview – preview .csv data quickly and easily in browser to see if this is the dataset you want.
Revision history – CKAN allows you to display a revision history for datasets which are freely editable by users (as is thedatahub.org)
Extra fields – these hold any additional information, such as location data (see geospatial feature) or types relevant to the publisher or dataset. How and where extra fields display is customizable.
Licence – instant view of whether the data is available under an open licence or not. This makes it clear to users whether they have the rights to use, change and re-distribute the data.
Tags – see what labels the dataset in question belongs to. Tags also allow for browsing between similarly tagged datasets in addition to enabling better discoverability through tag search and faceting by tags.
Multiple formats (if provided) – see the different formats the data has been made available in quickly in a table, with any further information relating to specific files provided inline.
API key – allows access every metadata field of the dataset and ability to change the data if you have the relevant permissions via API.