
In Category on 13 Jun 2026
CKAN 2.12 is coming: how you can help get it over the line
The release process has started — here is how you can contribute
API (reading and writing): This is quite important for a modular and flexible infrastructure. We also want to provide integration packages for other systems (CMS or special e-journal software). We think that research data must not just be stored in, perhaps closed, 'data-silos', but should be accessible and reusable as much as possible. An API opens up a lot more possibilities for this purpose.
Simple User Interface: We are mainly targeting authors and editorial offices who don't have the time, resources and know-how to learn and use complicated UIs and workflows. This is also important for lowering the general barriers for publishing research data.
RDF metadata representation: We are aware that this might be a somewhat 'avant-garde' criterion. But we predict that it will be more and more important in the near future to have a general, linkable and machine-readable metadata interface, so our research data can be used and adopted as widely as possible.
The main 'opponents' of CKAN in this small 'contest' were Dataverse and Nesstar. But while both are well established platforms dedicated especially to research data (which CKAN is not), neither met most of our criteria. Nesstar is proprietary, not open software, you have to pay for the server component, and the only way to upload data is the use of the so called 'Publisher', a Windows-only client. That's a no-go for us. Dataverse's main problem compared to CKAN (besides the fact that it is an unfriendly Java-beast of software ;-) is the lack of a decent API. There is at least now a reading API (since March 2012), but you cannot use it to upload data. So, in the end there was no question which software we would choose: CKAN. Let's see in detail why.
apt-get. The package installation will do all necessary basic configurations for you, so it might be more convenient. However, this method also involves some lack of flexibility, so we would not recommend it. Moreover, if you may want to develop your own CKAN extension (more on that later) or use another OS platform, you must use the second method and install CKAN from source. I didn't find that to be too difficult and, again, if you have some experience as developer it will be no real problem. In this scenario CKAN will be installed via git and pip in a virtualenv, which you will most probably already be familiar with. The application then is ran with paster. Under the hood, CKAN uses the Python framework Pylons (which has now merged with another framework and is called Pyramid; but that's another story).
In addition to the core package of CKAN, you will have to install and configure some packages that CKAN requires. Nothing fancy here, though. CKAN uses PostgreSQL as its database, and for searching and indexing it relies on Solr, which involves the installation of a Java JDK and a Java application server like Jetty or Tomcat. It's worth mentioning that you can run CKAN without Solr, but you'll lose a lot of advanced search functionality like faceting for instance. The same goes for the database. Besides the almighty PostgreSQL you can also use the lightweight SQLite. This is quite handy for testing purposes or for development, but not recommended or supported for production installations.
get a full metadata representation of any dataset or resource (which is the actual data or file);
do all the kinds of searches you can do with the web interface;
create, update and delete datasets, resources and other objects. I'm emphasizing this because it's really a killer feature, which enables you to develop your very own application based on API calls to an external CKAN installation. It makes, for example, mobile apps possible. Or you can write plugins for your local CMS, journal system or whatever.
From a programmer's perspective this is just great, great, great. And even with our focus, open research data management, it enables a lot more usage scenarios than a simple web portal with a closed, proprietary database would do.
And in fact, it is quite easy to use the API. There are client libraries for any common web programming language (Python, Java, Perl, PHP, Javascript, Ruby), so you don't need to write the basic functions on your own. A very simple Python script like the one below is sufficient to upload a file to a CKAN instance:
import ckanclient
CKAN = ckanclient.CkanClient(api_key=,
base_location=<url_of_CKAN_instance/api>)
upmsg = CKAN.upload_file()
print upmsg #this is not necessary ;-)
For demonstration and testing purposes we've developed a small sample application. It was built with the Pyramid framework and can completely manage the datasets of a certain group at an external CKAN instance. The demo pics show the list of the packages and a form to create a new dataset. Since this instance is for developing and evaluation purposes only it's not public, but hopefully the pics will give you a first impression of what's possible.
[caption id="" align="aligncenter" width="503"] Custom application using the API: list of packages[/caption]
[caption id="" align="aligncenter" width="304"]
Custom application using the API: list of packages[/caption]
[caption id="" align="aligncenter" width="304"] Pyramid app: add_form[/caption]
It's worth mentioning that, of course, writing your own application around the CKAN API also allows you to simply add features CKAN might not have. So, for instance, the little red X mark at the right side of all packages (screenshot #1) enables a direct deletion of the package. That's something CKAN's UI does not offer by default.
OK, you're saying, I got it, the API is great. But I don't want to program an external application. I just want to stick with the original platform, but I need a different look, and even more special functionalities. So, is CKAN extensible?
Short answer: Yes.
Pyramid app: add_form[/caption]
It's worth mentioning that, of course, writing your own application around the CKAN API also allows you to simply add features CKAN might not have. So, for instance, the little red X mark at the right side of all packages (screenshot #1) enables a direct deletion of the package. That's something CKAN's UI does not offer by default.
OK, you're saying, I got it, the API is great. But I don't want to program an external application. I just want to stick with the original platform, but I need a different look, and even more special functionalities. So, is CKAN extensible?
Short answer: Yes.
paster create -t ckanext ckanext-mycustomextensionckanext-, for otherwise CKAN won't detect and load your package. You then have to install it as a develop package in the Python path of your virtual environment. That's done the usual way with
cd <path_to_your_extension>
python setup.py developpip install -e <path_to_your_extension>ckanext-edawax, is mainly for the UI. It tweaks some templates and UI elements (logo, fonts, colors etc.). In addition it removes elements we do not need at the moment, like 'groups' or facet fields, and it renames the default 'Organizations' to 'Journals', since this is our only type of organization and we'd like to reflect this focus. We will also add new elements, like proposed citation in a dataset view. You can get the idea of the prototype with these screenshots.
[caption id="" align="aligncenter" width="535"]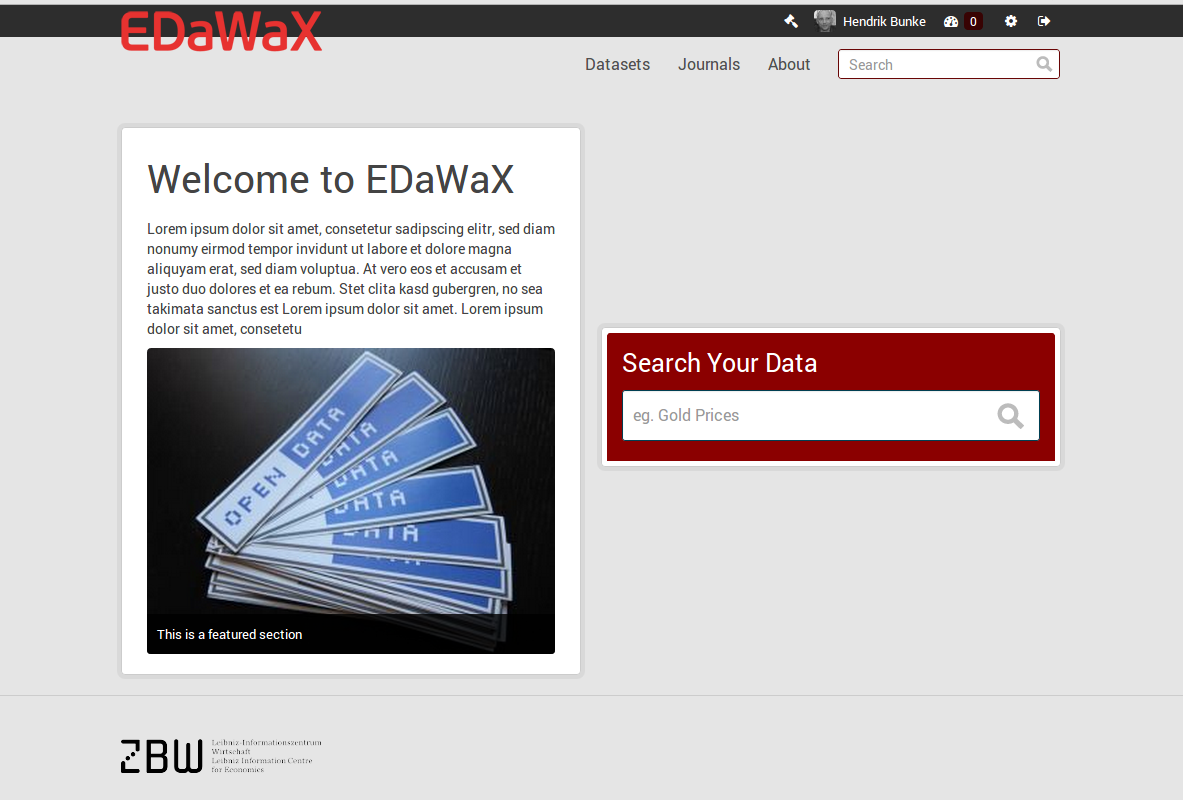 EDaWaX custom frontpage[/caption]
[caption id="" align="aligncenter" width="514"]
EDaWaX custom frontpage[/caption]
[caption id="" align="aligncenter" width="514"]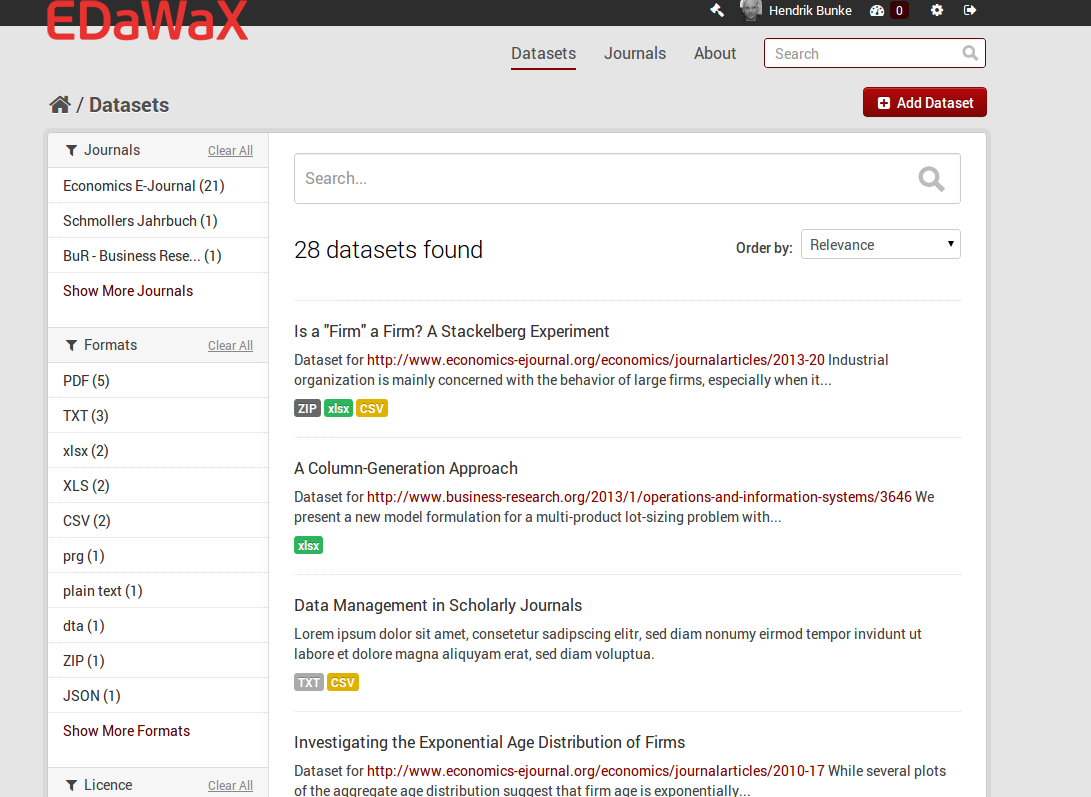 EDaWaX datasets view[/caption]
[caption id="" align="aligncenter" width="514"]
EDaWaX datasets view[/caption]
[caption id="" align="aligncenter" width="514"]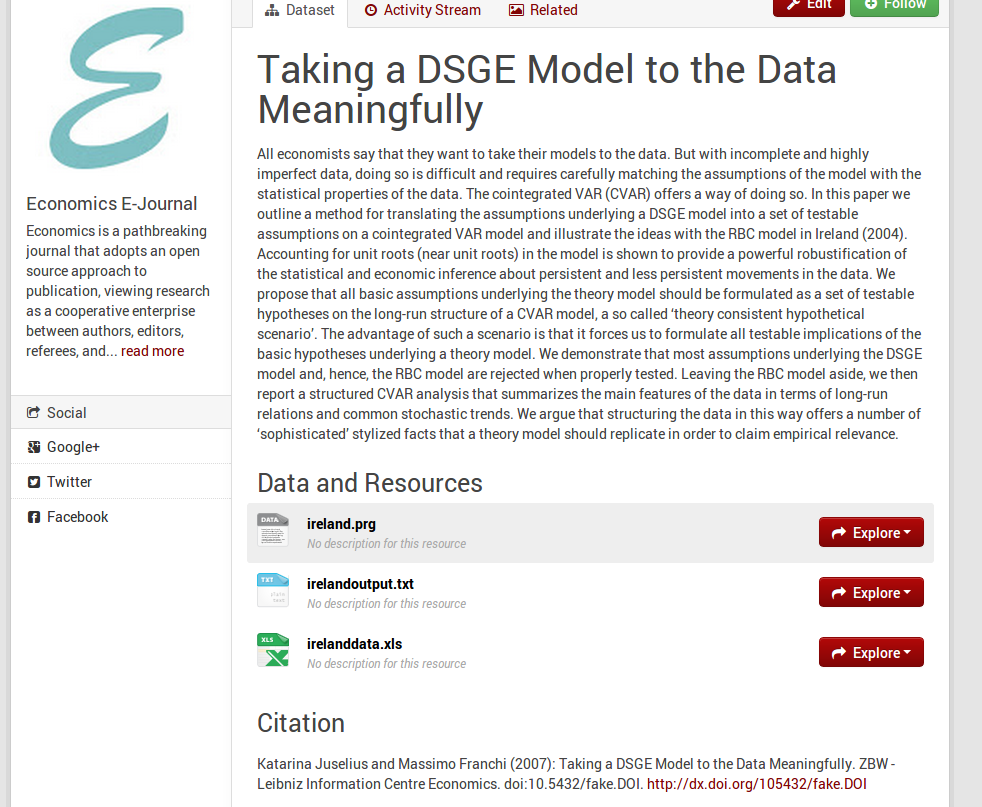 EDaWaX single dataset view[/caption]
Our second package,
EDaWaX single dataset view[/caption]
Our second package, ckanext-dara, relates to metadata. CKAN offers only a kind of general and limited set of metadata for datasets (like title, description, author), that does not reflect any common schema. You can, nevertheless, add arbitrary fields via the webinterface for each dataset. But that's not schema based. The approach of CKAN here is to avoid extensive metadata forms, that might restrict the usability of the portal, and also not to specialise on certain types or categories of data, like, you name it, research data. Dedicated research data applications like Dataverse do have an advantage here. Dataverse's metadata forms are based on the well-known and very extensive DDI schema. CKAN is not originally a research data management tool, and the lack of decent metadata schema support is one point where this hurts. However, this more general approach as well as the plugin infrastructure (a feature that Dataverse does not offer, AFAIK) enables us to customise the dataset forms, add specific (meta‑)data, and to guarantee compatibility with a given schema. For EDaWaX this will be the da|ra schema, which itself is partially based on the well-known, but less complex data-cite schema. The German based da|ra is basically a DOI registration service for social science and economic data. Since we will automatically register DOIs for our datasets in the CKAN portal with da|ra it makes perfectly sense that we use their schema (which we must do anyway when submitting our metadata).
ckanext-dara is the CKAN-extension where all the metadata functionality as well as the DOI registration will be added. It is also planned to publish this package as Open Source on github. So far the development has concentrated on extending the standard CKAN dataset forms with da|ra specific metadata. The problem here is the conflict between usability and the aspiration to get as much metadata as possible. You know, we are working in a library. For librarians metadata is important. Very important. You could say that librarians think in metadata. We want every single detail of an object to be described in metadata, if possible in very cryptic metadata. Since metadata schemas are often (if not always) created by librarians, they tend to be kind of exhaustive. The current da|ra schema knows more than 100 elements, which is only a small set compared to DDI which knows up to 846 elements. Now please imagine you're a scientist or the editor of a scientific journal who is asked to upload research data to our CKAN based platform. Would you like to see a form that asks for ~100 metadata elements? You certainly wouldn't. Chances are good that you would immediately (and perhaps cursing) leave the site and forget about this open data thing for the next two decades or so.
To deal with this conflict we are following a twofold approach. First, we are dividing the da|ra metadata schema into three levels reflecting the necessity. Level 1 contains very basic metadata elements that are mandatory, like title, main author, or the publication year. These fields of level 1 correspond to the mandatory fields of the DataCite metadata schema. For this level we only need two or three new fields in addition to the ones that are already implemented in CKAN. Level 2 contains elements that are necessary (or perhaps better: desirable) for the searchability of the dataset or special properties of it. And finally Level 3 reflects the special metadata we need to ensure future reuse by integrating authority files. By integrating these authority files it should be possible to link persons to their affiliations, to articles, research data, to keywords or to special fields of research.
Second, we will try to integrate these different levels of metadata as seamlessly as possible into CKAN’s UI. The general idea behind this is to give users the choice of which metadata functionalities they would like to equip their data with. To achieve this we collapse the subforms for level 2 and level 3 in the dataset form with a little help from jquery. The following screenshots give you an idea. Please note that this is an early stage of development and nothing's finalised yet. We have not implemented level 3 yet. However, you can see that the form for level 2 (as well as later for level 3) is collapsed by default, so the "quick'n'dirty" user won't have to deal with it if she does not want to. We are still thinking, however, about the motivation/information text and its presentation.
[caption id="" align="aligncenter" width="514"]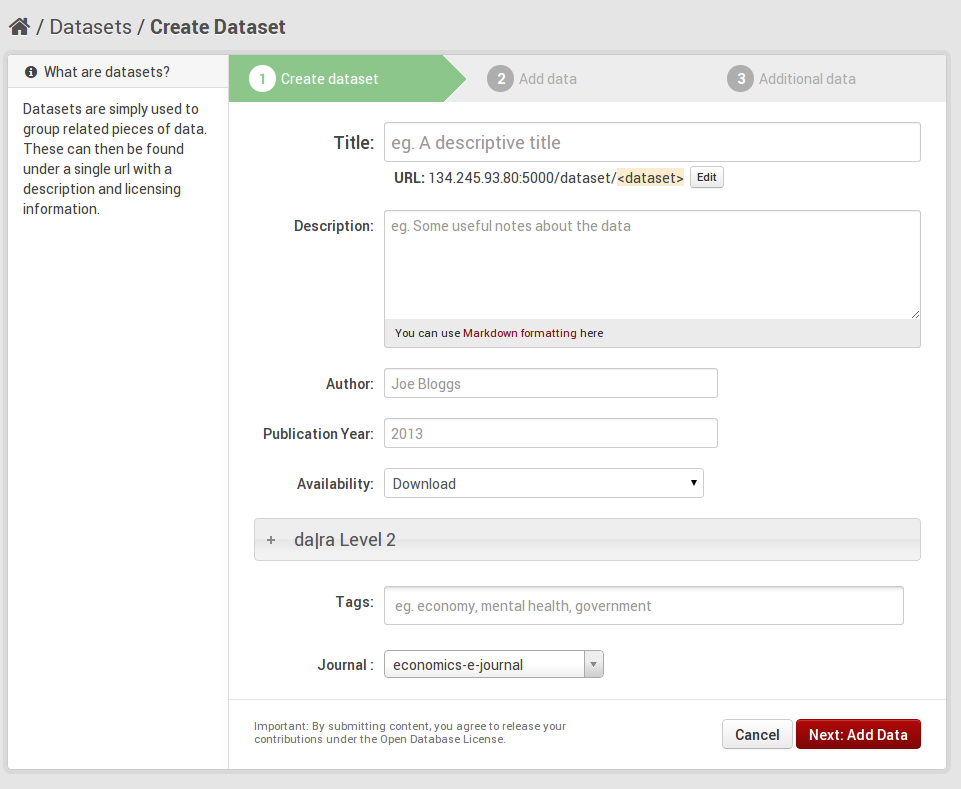 ckanext-dara addform[/caption]
[caption id="" align="aligncenter" width="521"]
ckanext-dara addform[/caption]
[caption id="" align="aligncenter" width="521"]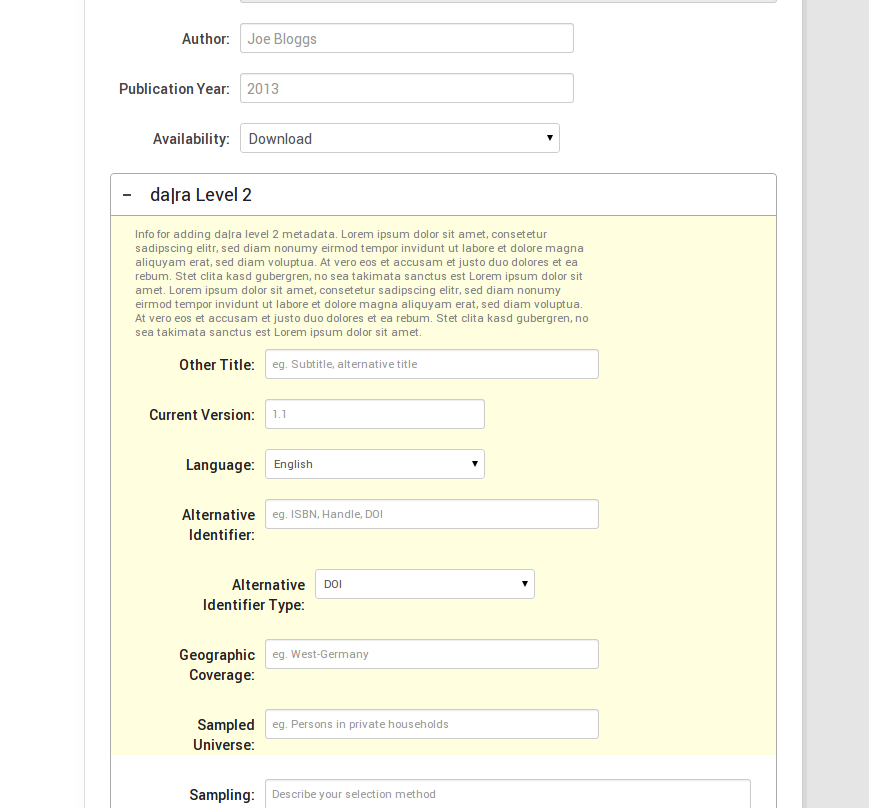 ckanext-dara addform extended[/caption]
ckanext-dara addform extended[/caption]
h.bunke zbw.eu in case you have a more specific question.
The release process has started — here is how you can contribute

From NYCBigApps to federal metadata standards — a co-founder's story of why CKAN's real value was never the portal